Analyse automatisée du nerf optique
Contexte
Le nerf optique qui relie la rétine aux aires visuelles du cerveau est constitué d’environ un million d’axones chez l’être humain. Ce nombre peut atteindre plusieurs millions chez les oiseaux. Le nerf optique demeure à bien des égards une terra incognita car son étude est difficile chez les primates. Les oiseaux peuvent nous aider à répondre à plusieurs questions clés. Ce sont les axones des cellules ganglionnaires (CG) qui forment le nerf optique et qui sont responsables de transmettre le signal nerveux de la rétine au cerveau. Le comptage des axones sur des tranches de nerf optique est l’une des méthodes les plus sûres pour connaître le nombre de CG dans la rétine.
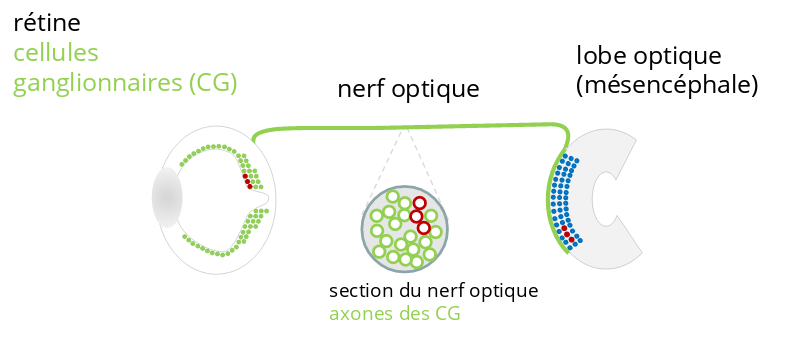
Les axones sont distribués dans le nerf optique selon une carte rétinotopique produisant dans le cerveau une représentation dite homéomorphe du champ visuel. En d’autres termes, une image vue par l’oeil est transférée de la rétine jusqu’au lobe optique dans le cerveau en ne subissant qu’une déformation progressive et continue ; imaginez pour cela une image imprimée sur la membrane d’un ballon gonflable. Vous pouvez alors déformer l’image en étirant la membrane de diverses manières, en la repliant, en la torsadant sans toutefois jamais la déchirer. Vous obtenez alors une image qui a été continûment déformée mais n’ayant subi aucune rupture. Cela signifie que deux points situés côte à côte sur l’image de départ resteront côte à côte durant tout le processus de projection de l’image jusque dans dans le cerveau.
Pour cette raison, le nombre et la distribution des axones de grands et de petits diamètres au sein du nerf optique fournissent des informations sur le nombre et la distribution des cellules ganglionnaires de différents types, comme en particuliers les CG naines (appelés P-CG) et les CG géantes (appelées M_CG ou CG-parasol) au sein de la rétine.
Objectifs
Effectuer une analyse morphométrique du nerf optique demande d’identifier les axones qui le constituent pour pouvoir ensuite étudier leur nombre, leur taille, leur organisation au sein du nerf optique, etc. Il s’agit pour cela de détecter et de marquer de la manière la plus précise possible les contours de tous les axones traversant une section transversale d’un nerf optique qui a été au préalable photographiée au microscope. Étant donné le nombre considérable d’axones constituant un nerf optique, effectuer cette tâche manuellement serait extrêmement long et fastidieux. Notre objectif est donc de développer une méthode de détection automatisée.

Approche
Nous envisageons d’appliquer des algorithmes d’intelligence artificielle en utilisant une technique que l’on appelle la segmentation d’images. La segmentation d’images est un exemple d’apprentissage supervisé : on présente dans un premier temps à l’algorithme une série d’images accompagnées d’annotations manuelles, comme dans la figure suivante :
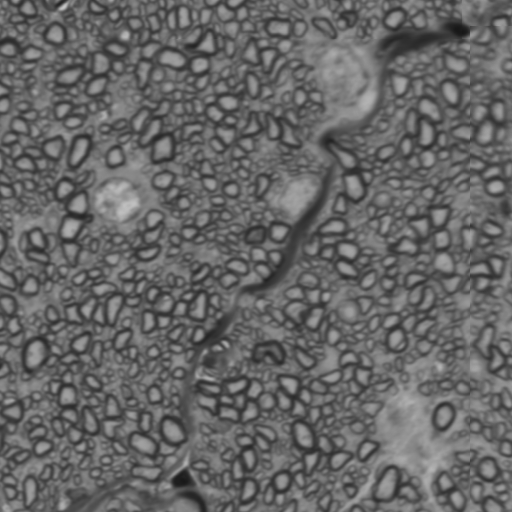

L’annotation manuelle consiste dans notre cas à préparer pour chaque image un masque noir et blanc qui identifie les éléments devant être détectés, à savoir les axones, marqués ici en blanc. L’algorithme va alors s’entraîner à reproduire le plus fidèlement possible chacun des masques – c’est la phase d’apprentissage. L’objectif de cette phase est que l’algorithme apprenne à produire des masques noirs et blancs fidèles à partir d’images nouvelles qui lui seront présentées par la suite sans aucune annotation – c’est la phase de prédiction.
À partir d’un masque noir et blanc de qualité comme celui représenté dans la figure précédente à droite, il est possible d’identifier efficacement et automatiquement les contours des axones pour étudier leur taille, leur forme et leur agencement au sein du nerf optique. Cela est illustré dans la figure ci-dessous :
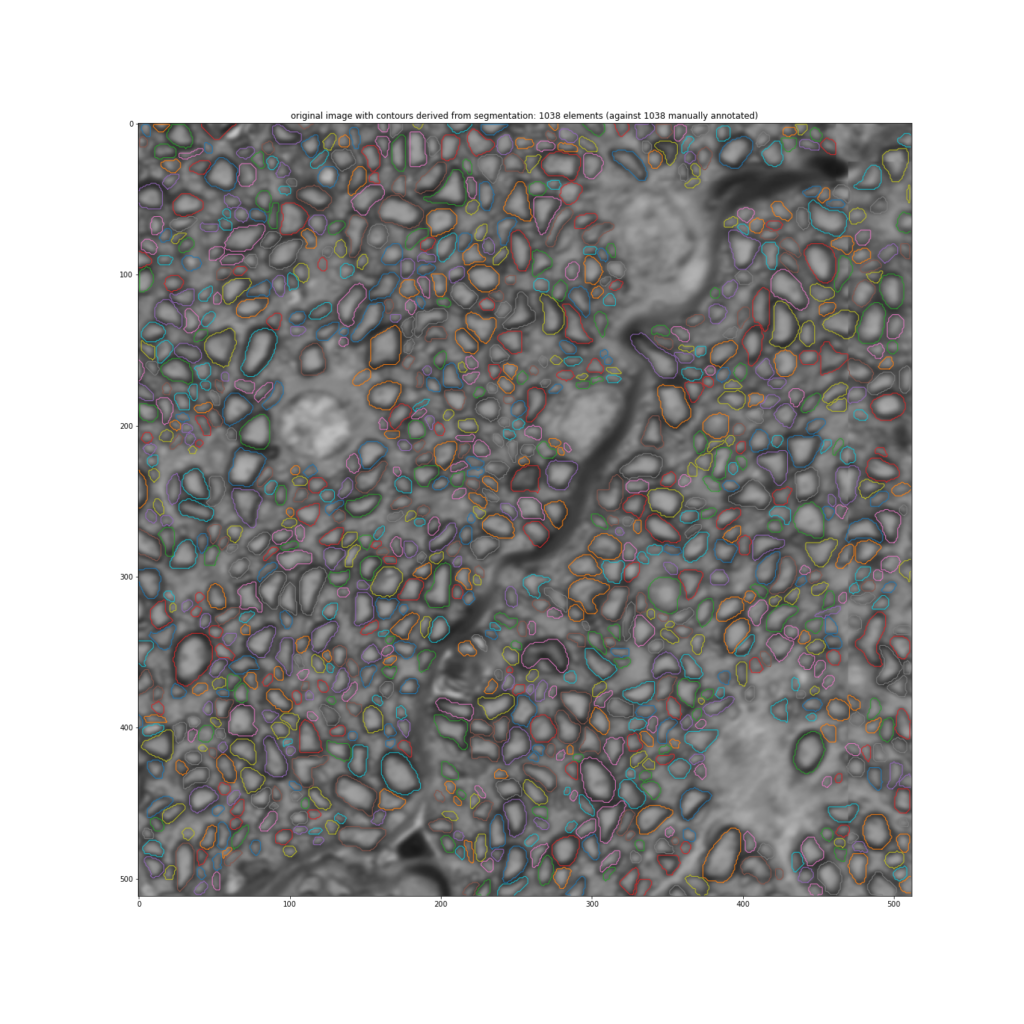
L’algorithme utilisé pour produire les masques noirs et blanc à partir d’images est ce qu’on appelle un réseau de neurones convolutionnel. Un réseau de neurones est une construction mathématique organisée en couches successives où le rôle de chacune des couches est de détecter des traits géométriques différents. Chaque couche est constituée d’éléments appelés « neurones ». Les neurones appartenant à deux couches successives sont connectés entre eux en sorte que l’information recueillie par une couche est transmise à la couche suivante. Les premières couches apprennent à détecter des formes géométriques simples comme des segments horizontaux ou verticaux, des arcs de cercle, etc., tandis que les couches plus profondes reprennent l’information transmises par les couches précédentes pour détecter des formes géométriques de plus en plus complexes pour finalement parvenir à détecter la présence et la localisation au sein de l’image des éléments que l’on souhaite identifier.
Enjeux de cette approche
L’enjeu pour construire et entraîner un réseau de neurones qui fonctionne bien est double : il faut d’une part choisir une architecture, c.-à-d. une manière d’organiser les différentes couches, leur nombre et la manière dont les neurones les constituant sont interconnectés, qui soit adaptée au type d’image que l’on souhaite analyser. D’autre part, il est nécessaire de fournir à l’algorithme une quantité suffisante d’images annotées manuellement pour qu’il apprenne à généraliser, c’est à dire produire des masques fidèles à partir d’images qu’il n’a jamais vues auparavant.
La quantité d’images nécessaire à un bon apprentissage dépend du type d’images à analyser ainsi que de la complexité du réseau de neurones utilisé, et peut varier de plusieurs dizaines à plusieurs milliers. La constitution d’un jeu d’images d’entraînement suffisamment grand peu donc s’avérer une tâche longue et fastidieuse. Toutefois, des techniques d’augmentation de données visant à contourner cet obstacle existent et sont couramment utilisées dans le domaine de la bioimagerie où le nombre d’images manuellement annotées est souvent restreint. Ces techniques consistent à réutiliser plusieurs fois une même image annotée en la modifiant légèrement à l’aide de transformations géométriques commes des rotations, des translations ou des distorsions.
Nous allons nous baser sur une architecture de réseau de neurones déjà existante, appelée U-Net ( arXiv:1505.04597 ), qui a été développée dans le but de faire de la segmentation d’images biomédicales. Toutefois, les tissus cellulaires pouvant avoir des aspects très différents selon leur nature, il sera sans doute nécessaire pour obtenir de bons résultats d’adapter cette architecture afin d’exploiter au mieux les caractéristiques morphologiques spécifiques au nerf optique. En outre, il sera nécessaire de fournir à l’algorithme un ensemble suffisamment grand d’images accompagnées de masques produits manuellement pour entraîner efficacement l’algorithme à produire des masques fidèles à partir d’images nouvelles. Nous allons également utiliser les techniques d’augmentation de données évoquées précédemment pour amplifier notre ensemble d’entraînement.
Résultats préliminaires
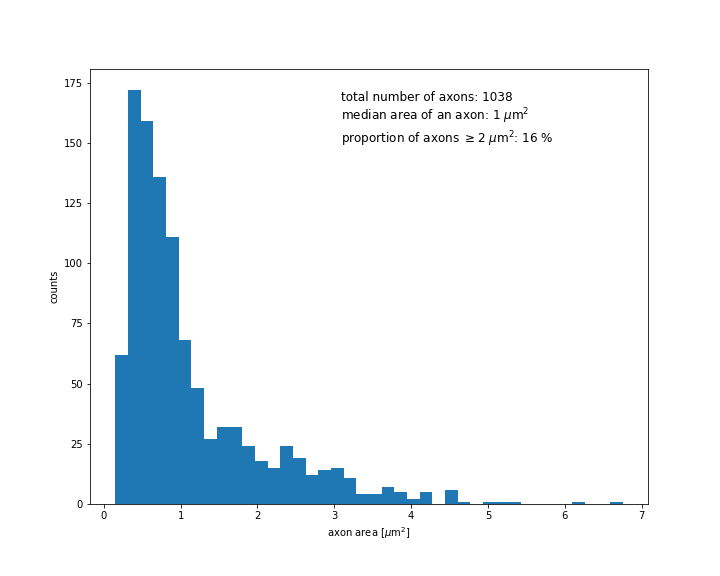
Les résultats préliminaires d’entraînement du réseau de neurones sur un ensemble d’entraînement très restreint de huit images seulement, mais amplifié à l’aide d’une technique d’augmentation de données sont prometteurs, comme on peut le voir sur la figure suivante :

Les prochaines étapes consisteront dans un premier temps à augmenter la taille de l’ensemble d’entraînement. On se concentrera ensuite sur l’optimisation de l’architecture du réseau de neurones utilisé afin d’augmenter sa performance.